Gradient Descent and Delta Rule, Derivation of Delta Rule for Artificial Neural Networks in Machine Learning – 17CS73
Video Tutorial
Gradient Descent and Delta Rule

A set of data points are said to be linearly separable if the data can be divided into two classes using a straight line. If the data is not divided into two classes using a straight line, such data points are said to be called non-linearly separable data.
Although the perceptron rule finds a successful weight vector when the training examples are linearly separable, it can fail to converge if the examples are not linearly separable.
A second training rule, called the delta rule, is designed to overcome this difficulty.
If the training examples are not linearly separable, the delta rule converges toward a best-fit approximation to the target concept.
The key idea behind the delta rule is to use gradient descent to search the hypothesis space of possible weight vectors to find the weights that best fit the training examples.
This rule is important because gradient descent provides the basis for the BACKPROPAGATON algorithm, which can learn networks with many interconnected units.
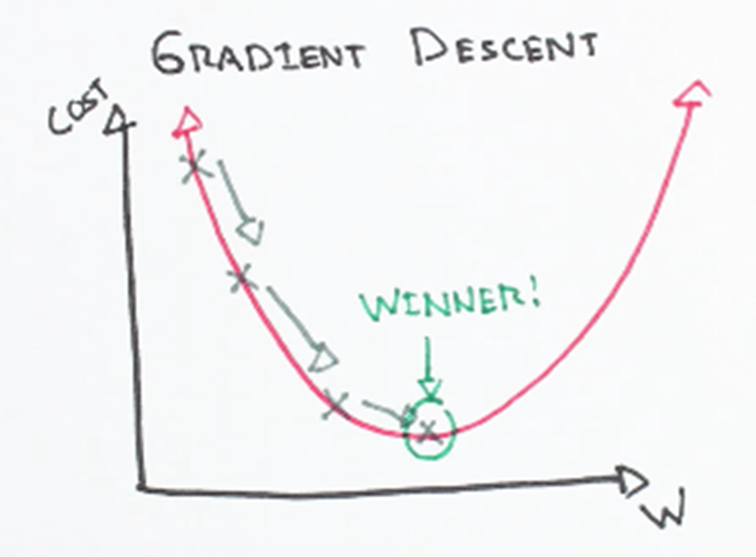
Derivation of Delta Rule
The delta training rule is best understood by considering the task of training an unthresholded perceptron; that is, a linear unit for which the output o is given by

Thus, a linear unit corresponds to the first stage of a perceptron, without the threshold.
In order to derive a weight learning rule for linear units, let us begin by specifying a measure for the training error of a hypothesis (weight vector), relative to the training examples.
Although there are many ways to define this error, one common measure is
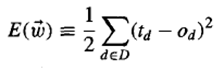
where D is the set of training examples, ‘td’ is the target output for training example ‘d’, and od is the output of the linear unit for training example ‘d’.
How to calculate the direction of steepest descent along the error surface?
The direction of steepest can be found by computing the derivative of E with respect to each component of the vector w. This vector derivative is called the gradient of E with respect to w, written as,
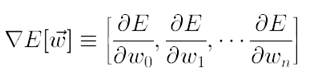
The gradient specifies the direction of steepest increase of E, the training rule for gradient descent is

Here η is a positive constant called the learning rate, which determines the step size in the gradient descent search.
The negative sign is present because we want to move the weight vector in the direction that decreases E.
This training rule can also be written in its component form,

Here,

Finally,

Summary
This tutorial discusses the Gradient Descent and Delta Rule Derivation in Machine Learning. If you like the tutorial share it with your friends. Like the Facebook page for regular updates and YouTube channel for video tutorials.